overleaf template galleryLaTeX templates and examples — Recent
Discover LaTeX templates and examples to help with everything from writing a journal article to using a specific LaTeX package.

A comprehensive template for M.Sc. or Ph.D. thesis with .bib, syntax-highlighted codes, hyperlink integration, and many more. The style is optimized for Tohoku University graduate students but can be customized for other purposes.

Letter template for The Australian National University.

This is the english bachelor thesis template for University of Applied Sciences Salzburg.

Контрольная работа по правоведению

This is a template for preparing presentation slides at Carleton College.

The official template for UbiComp conference papers and notes. Retrieved from the guidelines for UbiComp 2013 on 28 Nov, 2013.
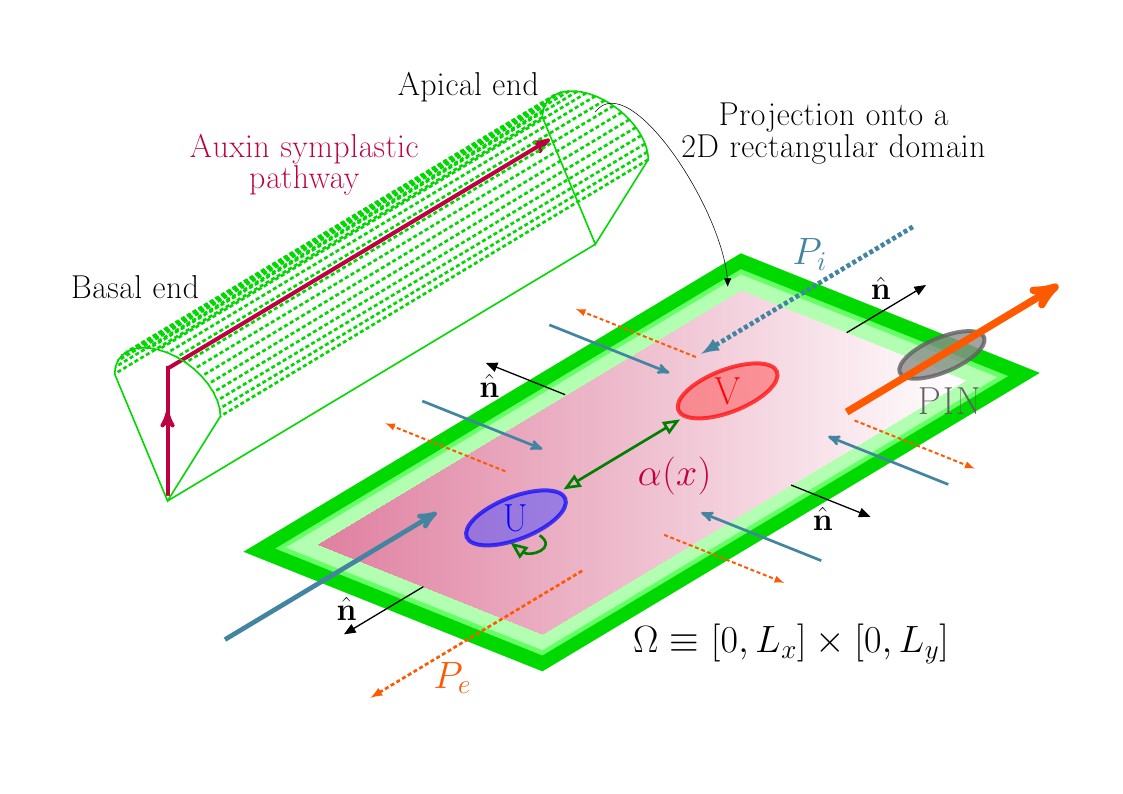
A TikZ figure using the beamerposter package. It shows an idealised 3D root hair cell, and its projection onto a 2D rectangular domain. The auxin symplastic pathway is indicated by purple arrows and the longitudinal auxin gradient by a shade in the 2D-domain; influx and efflux permeability arrows, indicating a polarising process, are respectively depicted in orange and light-blue. Switching fluctuation is represented by dark green arrows.

Add inline or margin comments to LaTeX pdfs using the todonotes package.

LaTeX beamer theme for Jilin University students. Chinese support. This template mostly comes from Jiayi Weng, Trinkle23897. His github repo is https://github.com/Trinkle23897/THU-Beamer-Theme. Thank you very much Trinkle! My github repo is https://github.com/GohUnTsuan/JLU-Beamer-Theme
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.