LaTeX templates and examples — Essay
Recent

This is an unofficial template for writing essays, reports, thesis or any other academic writings.

Principios de desarrollo ideal en el ajedrez
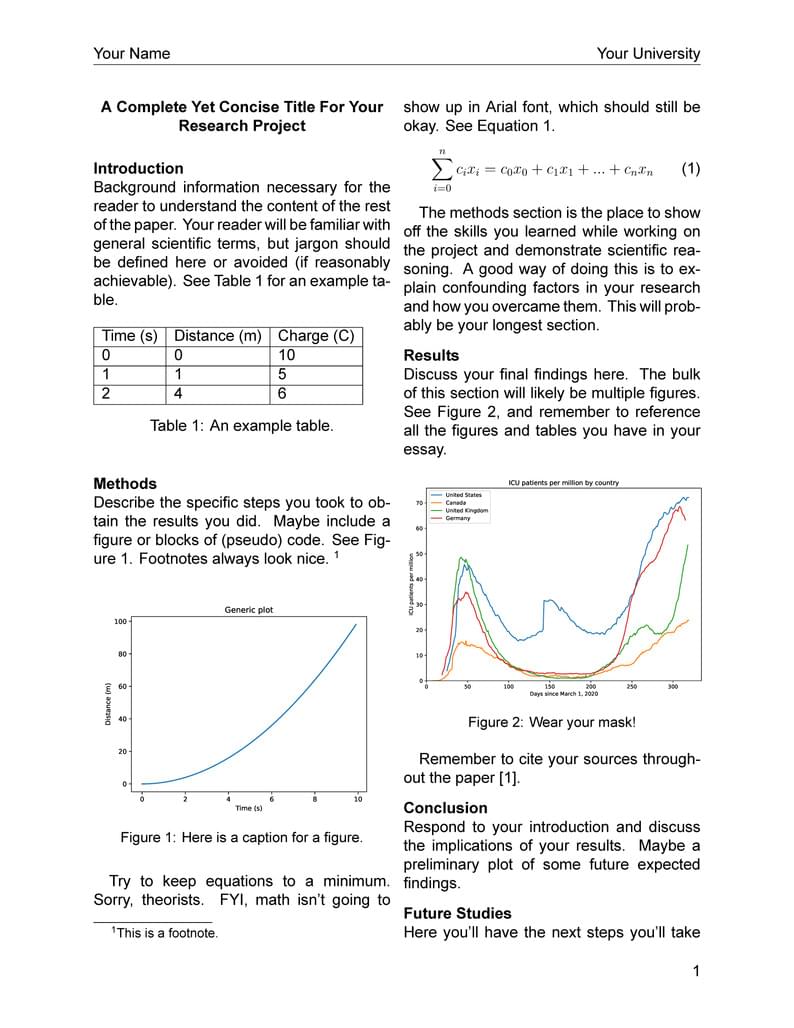
I made this template based off my successful Goldwater Scholarship research essay in 2019. If nothing about the formatting has changed since then, it should be good to go. You can find my completed essay here: https://www.overleaf.com/latex/templates/goldwater-scholarship-research-essay-example/fnmwcnpvxgbg
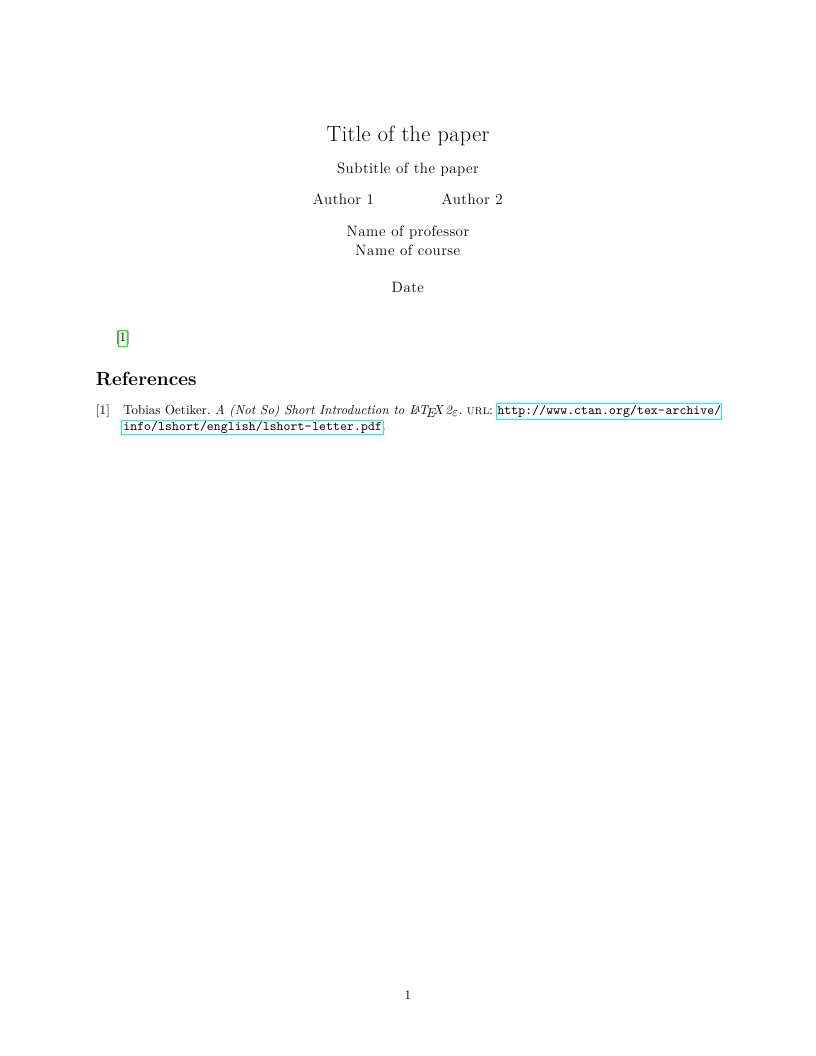
This is a template for writing essays at Carleton College.

The accelerated rate of growth in the amount of web applications returns as a result an increase in the traffic that web servers must handle. This aggregated traffic, in addition to the demand of the clients to be served in a real time frame, leads to the requirement of a customized way to control web related resources. All processes of the web server are tied to the control that the OS scheduler has over them, and for the default settings, the scheduler is set to handle general purpose tasks instead of being optimized forweb serving purposes. To address this issue, the use of custom settings into the scheduler will allow the daemons needed to run a web page (such as Apache, PHP and a SQL DB) to be handled by the OS as efficiently as possible. The results of the test will be the comparison in performance of a web server for different settings on the Linux Scheduler.

Consumo de Alimentos Provenientes de Animales: el Mayor y Más Ignorado Factor Contaminante

a report for PMB

Русскоязычный шаблон для рефератов по ГОСТ 7.32-2017 "Отчет о научно-исследовательской работе". Подготовлен по рекомендациям сотрудников и преподавателей Университета ИТМО для студентов технических и естественно-научных специальностей. Шаблон составлен для компилятора XeLaTeX, библиография собирается при помощи движка biber. Работоспособность проверялась в Overleaf и на Windows 11 в связке MikTeX + TeXstudio.

Template de Artigo Científico desenvolvido de acordo com as normas de trabalho acadêmico do Instituto Federal de Educação, Ciência e Tecnologia de Brasília.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.