Community articles — Journal articles
Discover a wide range of academic journal LaTeX templates for articles and papers which automatically format your manuscripts in the style required for submission to that journal.
Recent

The Electricity theft is an economic issue for the electricity company due to unbilled revenue of consumers who commit such action. In a regulated scenario the company needs to fit within the laws of a regulatory agency (ANEEL in Brazil) and the loss of revenue is a problem that can compromise the compliance with regulatory targets and business efficiency. The objective of this article is to analyze how the energy theft impacts on the economy of the regulated company, consumers and society as a whole. Through the economic model Tarot (Optimized Tariff) it was possible through a concise and comprehensive manner to analyze the regulated electricity market using simulations and discover in which points the company operates optimally and through it to determine the economic indicators.
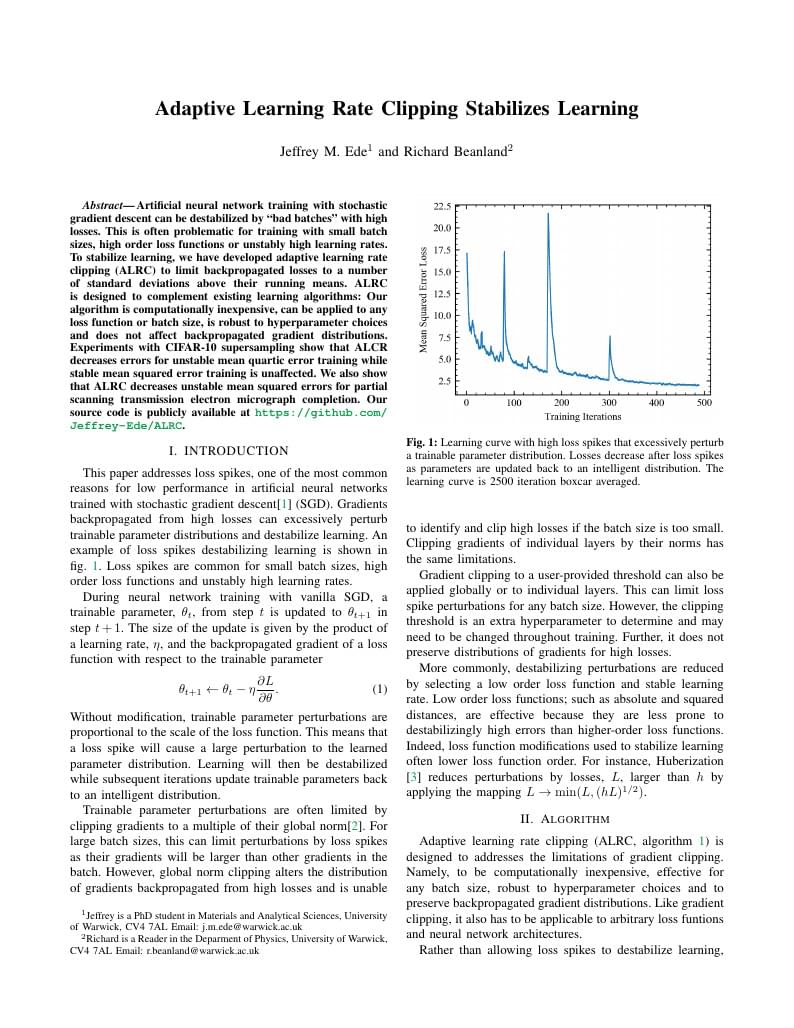
Adaptive learning rate clipping (ALRC) stabilizes learning by limiting backpropagated losses.

The efficiency of a query execution plan depends on the accuracy of the selectivity estimates given to the query optimiser by the cost model. The cost model makes simplifying assumptions in order to produce said estimates in a timely manner. These assumptions lead to selectivity estimation errors that have dramatic effects on the quality of the resulting query execution plans. A convenient assumption that is ubiquitous among current cost models is to assume that attributes are independent with each other. However, it ignores potential correlations which can have a huge negative impact on the accuracy of the cost model. In this paper we attempt to relax the attribute value independence assumption without unreasonably deteriorating the accuracy of the cost model. We propose a novel approach based on a particular type of Bayesian networks called Chow-Liu trees to approximate the distribution of attribute values inside each relation of a database. Our results on the TPC-DS benchmark show that our method is an order of magnitude. more precise than other approaches whilst remaining reasonably efficient in terms of time and space.

We all have a good reason to learn a new language; discovering our roots, passion for travel, academic purposes, pure interest etc. However most of us find it hard to become conversationally fluent in a new language while we use traditional resources for learning like textbooks and tutorials on the internet. In this paper we propose a novel approach to learn a new language. We aim to develop an intelligent browser extension, LanGauger, that will help users learn foreign languages. This application will allow users to look up words while they are browsing, by highlighting the text to be learned. The application will then provide a translation of the word, its pronunciation and its usage context in sentences. In addition, this intelligent tutor will also remember what words have been seen by the user, and quiz them on these words at appropriate times. While testing the recall of the user, this feature will also allow users to frequently think about the language and use it.
With Overleaf, edit online instantly this IET Electronics Letters Journal example and download a PDF version. This project is also available on my web site

How to conceal objects from electromagnetic radiation has been a hot research topic. Radar is an object detection system that uses Radio waves to determine the range , angle, or velocity. A radar transmit radio waves or microwaves that reflect from any object in their path. A receive radar is typically the same system as transmit radar, receives and processes these reflected wave to determine properties of object. Different organizations are working onto hide object from the radar in outer space. Any confidential object can be taken through space without being detected by the enemies. This calls for necessity of devising new method to conceal an object electromagnetically.

Template: (c) 2010 Association for Computing Machinery (ACM) For tracking purposes => this is v1.3 - March 2012

En ésta páctica medimos y cuantificamos algunas de las propiedades de diferentes rocas, como la densidad y la masa, utilizando los equipos necesarios y comparándolas entre ellas para saber como es el comportamiento de las rocas que recolectamos. Al finalizar de hacer experimentos con las diferentes rocas, se compararon los resultados con los de otro equipo y se observ ́o que ambos resultados eran similares, lo que indica que cada tipo de roca tiene características diferentes de las demás, como su porosidad o densidad, independientemente de su masa o volumen.

With Overleaf, edit online instantly this IEEE Transactions on Microwave Theory and Techniques Journal example and download a PDF version. This project is also available on my web site
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.